Ang istraktura ng transport RNA. Mga uri ng RNA, mga pag-andar at istraktura
Ang Aminoacyl-tRNA synthetase (ARSase) ay isang synthetase enzyme na nag-catalyze sa pagbuo ng aminoacyl-tRNA sa esterification reaction ng isang partikular na amino acid na may katumbas na tRNA molecule nito. Ang bawat amino acid ay may sariling aminoacyl-tRNA synthetase. Ang mga ARSases ay nagbibigay ng sulat sa mga nucleotide triplets ng genetic code (tRNA anticodon) ng mga amino acid na ipinasok sa protina, at sa gayon ay tinitiyak ang tamang pagbabasa ng genetic na impormasyon mula sa mRNA sa panahon ng synthesis ng protina sa mga ribosome. Karamihan sa mga APC-ases ay binubuo ng 1, 2 o 4 na magkaparehong polypeptide chain. Ang molecular weight ng polypeptide chain ay 30-140 thousand. Maraming APC-ases ang naglalaman ng dalawang aktibong sentro. May 3 plots. Ang 1st site ay walang specificity, ito ay pareho para sa lahat ng enzymes, ito ang site ng ATP attachment. Ang nth site ay may mahigpit na pagtitiyak, ang isang tiyak na AK ay naka-attach dito, ayon sa kung saan ang ARSase ay tinatawag, halimbawa, kung ito ay nakakabit ng methionine, kung gayon ito ay tinatawag na methionyl-t-RNA synthetase. Ang sh-th site ay isa ring mahigpit na partikular na site, maaari lamang itong kumonekta sa isang tiyak na t-RNA. Kaya, ang enzyme ay kinakailangan para sa pagkilala ng mga amino acid at tRNA.
Ang pagtitiyak ng mga reaksyon na na-catalyze ng APCases ay napakataas, na tumutukoy sa katumpakan ng synthesis ng protina sa isang buhay na cell. Kung ang A. ay nagsasagawa ng maling aminoacylation ng tRNA na may amino acid na katulad ng istraktura, ang isang pagwawasto ay magaganap sa pamamagitan ng catalyzed ng parehong APC-ase hydrolysis ng maling AK-tRNA sa AA at tRNA. Ang cytoplasm ay naglalaman ng isang kumpletong hanay ng mga APCases, habang ang mga chloroplast at mitochondria ay may sariling APCases.
transport RNA. Istraktura, mga pag-andar. Ang istraktura ng ribosome.
Ang lahat ng mga tRNA ay may mga karaniwang tampok pareho sa kanilang pangunahing istraktura at sa paraan ng polynucleotide chain ay nakatiklop sa isang pangalawang istraktura dahil sa mga pakikipag-ugnayan sa pagitan ng mga base ng nucleotide residues.
Pangunahing istraktura ng tRNA
Ang mga tRNA ay medyo maliit na molekula, ang haba ng kanilang kadena ay nag-iiba mula 74 hanggang 95 na mga nalalabi sa nucleotide. Ang lahat ng tRNA ay may parehong 3'-end, na binuo mula sa dalawang cytosine at isang adenosine residues (CCA-end). Ito ang 3'-terminal adenosine na nagbubuklod sa residue ng amino acid sa panahon ng pagbuo ng aminoacyl-tRNA. Ang dulo ng CCA ay nakakabit sa maraming tRNA ng isang espesyal na enzyme. Ang nucleotide triplet na pantulong sa codon para sa amino acid (anticodon) ay matatagpuan humigit-kumulang sa gitna ng tRNA chain. Ang parehong (konserbatibo) nucleotide residues ay matatagpuan sa ilang mga posisyon ng sequence sa halos lahat ng mga uri ng tRNA. Ang ilang mga posisyon ay maaaring maglaman lamang ng purine o mga baseng pyrimidine lamang (tinatawag itong mga semi-conservative na residues).
Ang lahat ng mga molekula ng tRNA ay nailalarawan sa pagkakaroon ng isang malaking bilang (hanggang sa 25% ng lahat ng nalalabi) ng iba't ibang binagong mga nucleoside, na kadalasang tinatawag na mga menor de edad. Ang mga ito ay nabuo sa iba't ibang mga site sa mga molecule, sa maraming mga kaso na mahusay na tinukoy, bilang isang resulta ng pagbabago ng mga ordinaryong nucleoside residues sa tulong ng mga espesyal na enzymes.
Pangalawang istraktura ng tRNA
ang pagtitiklop ng kadena sa isang pangalawang istraktura ay nangyayari dahil sa magkaparehong complementarity ng mga seksyon ng kadena. Tatlong fragment ng kadena ay pantulong kapag sila ay nakatiklop sa kanilang mga sarili, na bumubuo ng mga istruktura ng hairpin. Bilang karagdagan, ang 5" na dulo ay pantulong sa site na malapit sa 3" na dulo ng chain, kasama ang kanilang antiparallel arrangement; bumubuo sila ng tinatawag na acceptor stem. Ang resulta ay isang istraktura na nailalarawan sa pagkakaroon ng apat na stems at tatlong mga loop, na tinatawag na "dahon ng klouber". Ang isang tangkay na may isang loop ay bumubuo ng isang sanga. Sa ibaba ay isang anticodon branch na naglalaman ng anticodon triplet bilang bahagi ng loop nito. Sa kaliwa at kanan nito ay ang mga sanga ng D at T, ayon sa pagkakabanggit ay pinangalanan para sa pagkakaroon ng hindi pangkaraniwang conserved nucleosides dihydrouridine (D) at thymidine (T) sa kanilang mga loop. Ang mga pagkakasunud-sunod ng nucleotide ng lahat ng pinag-aralan na tRNA ay maaaring matiklop sa magkatulad na mga istruktura. Bilang karagdagan sa tatlong cloverleaf loops, isang karagdagang, o variable, loop (V-loop) ay nakahiwalay din sa tRNA structure. Malaki ang pagkakaiba ng laki nito sa iba't ibang tRNA, na nag-iiba mula 4 hanggang 21 nucleotides, at ayon sa kamakailang data, hanggang 24 na nucleotides.
Spatial (tertiary) na istraktura ng tRNA
Dahil sa pakikipag-ugnayan ng mga elemento ng pangalawang istraktura, nabuo ang isang tertiary na istraktura, na tinatawag na L-form dahil sa pagkakapareho sa Latin na titik L (Larawan 2 at 3). Sa pamamagitan ng base stacking, ang acceptor stem at cloverleaf T stem ay bumubuo ng isang tuluy-tuloy na double helix, at ang iba pang dalawang stem ay bumubuo ng anticodon at D stems ng isa pang tuluy-tuloy na double helix. Sa kasong ito, ang mga D- at T-loop ay nagiging malapit at pinagsama sa pamamagitan ng pagbuo ng karagdagang, madalas na hindi pangkaraniwang mga pares ng base. Bilang isang patakaran, ang mga konserbatibo o semi-konserbatibong nalalabi ay nakikibahagi sa pagbuo ng mga pares na ito. Ang mga katulad na tertiary na pakikipag-ugnayan ay nagtataglay din ng ilang iba pang bahagi ng L-structure
Ang pangunahing layunin ng paglilipat ng RNA (tRNA) ay upang maghatid ng mga activated amino acid residues sa ribosome at tiyakin ang kanilang pagsasama sa synthesized protein chain alinsunod sa programang isinulat ng genetic code sa matrix, o informational, RNA (mRNA).
Ang istraktura ng ribosome.
Ang mga ribosome ay mga pormasyon ng ribonucleoprotein - isang uri ng "pabrika" kung saan ang mga amino acid ay pinagsama-sama sa mga protina. Ang mga eukaryotic ribosome ay may sedimentation constant na 80S at binubuo ng 40S (maliit) at 60S (malalaking) subunits. Kasama sa bawat subunit ang rRNA at mga protina.
Ang mga protina ay bahagi ng mga subunit ng ribosome sa dami ng isang kopya at gumaganap ng isang structural function, na nagbibigay ng interaksyon sa pagitan ng mRNA at tRNA na nauugnay sa isang amino acid o peptide.
Sa pagkakaroon ng mRNA, ang mga subunit ng 40S at 60S ay nagsasama-sama upang bumuo ng isang kumpletong ribosome, ang masa nito ay halos 650 beses kaysa sa molekula ng hemoglobin.
Tila, tinutukoy ng rRNA ang pangunahing istruktura at functional na mga katangian ng ribosom, lalo na, tinitiyak ang integridad ng mga subunit ng ribosomal, tinutukoy ang kanilang hugis at isang bilang ng mga tampok na istruktura.
Ang unyon ng malaki at maliit na mga subunit ay nangyayari sa pagkakaroon ng messenger (messenger) RNA (mRNA). Karaniwang pinagsasama ng isang molekula ng mRNA ang ilang ribosom tulad ng isang string ng mga kuwintas. Ang ganitong istraktura ay tinatawag na polysome. Ang mga polysome ay malayang matatagpuan sa ground substance ng cytoplasm o nakakabit sa mga lamad ng magaspang na cytoplasmic reticulum. Sa parehong mga kaso, nagsisilbi sila bilang isang site para sa aktibong synthesis ng protina.
Tulad ng endoplasmic reticulum, ang mga ribosom ay natuklasan lamang gamit ang isang electron microscope. Ang mga ribosom ay ang pinakamaliit sa mga organel ng cell.
Ang ribosome ay may 2 mga sentro para sa paglakip ng mga molekula ng tRNA: mga sentro ng aminoacyl (A) at peptidyl (P), sa pagbuo kung saan ang parehong mga subunit ay kasangkot. Magkasama, ang mga sentro ng A at P ay binubuo ng isang 2-codon mRNA na rehiyon. Sa panahon ng pagsasalin, ang sentro A ay nagbubuklod sa aa-tRNA, ang istraktura nito ay tinutukoy ng isang codon na matatagpuan sa rehiyon ng sentrong ito. Ang istraktura ng codon na ito ay naka-encode sa likas na katangian ng amino acid na isasama sa lumalaking polypeptide chain. Ang P center ay inookupahan ng peptidyl-tRNA; Naka-link ang tRNA sa isang peptide chain na na-synthesize na.
Sa eukaryotes, mayroong 2 uri ng ribosome: "libre", matatagpuan sa cytoplasm ng mga cell, at nauugnay sa endoplasmic reticulum (ER). Ang mga ribosome na nauugnay sa ER ay responsable para sa synthesis ng "para sa pag-export" na mga protina na pumapasok sa plasma ng dugo at kasangkot sa pag-renew ng mga protina ng ER, ang Golgi apparatus membrane, mitochondria, o lysosomes.
Synthesis ng isang polypeptide molecule. pagsisimula at pagpapahaba.
Ang synthesis ng protina ay isang cyclic, multi-step, energy-dependent na proseso kung saan ang mga libreng amino acid ay napo-polimerize sa isang genetically determined sequence upang bumuo ng mga polypeptide.
Ang ikalawang yugto ng matrix protein synthesis, ang aktwal na pagsasalin na nangyayari sa ribosome, ay karaniwang nahahati sa tatlong yugto: pagsisimula, pagpahaba, at pagwawakas.
Pagtanggap sa bagong kasapi.
Ang pagkakasunud-sunod ng DNA na na-transcribe sa isang solong mRNA, na nagsisimula sa isang pag-scan sa dulo ng 5' at nagtatapos sa isang terminator sa dulo ng 3', ay isang yunit ng transkripsyon at tumutugma sa konsepto ng isang "gene". Ang kontrol sa pagpapahayag ng gene ay maaaring isagawa sa yugto ng pagsasalin - pagsisimula. Sa yugtong ito, kinikilala ng RNA polymerase ang promoter, isang fragment na 41-44 bp. Nagaganap ang transkripsyon sa direksyong 5`-3` o mula kaliwa hanggang kanan. Ang mga pagkakasunud-sunod na nasa kanan ng panimulang nucleotide, kung saan nagsisimula ang tRNA synthesis, ay itinalaga ng mga numerong may sign + (+1+2..) at ang nasa kaliwa na may sign - (-1,-2) . Kaya, ang rehiyon ng DNA kung saan nakakabit ang DNA polymerase ay sumasakop sa isang lugar na may mga coordinate na humigit-kumulang mula -20 hanggang +20. Ang lahat ng mga tagapagtaguyod ay naglalaman ng parehong mga pagkakasunud-sunod ng nucleotide, na tinatawag na konserbatibo. Ang ganitong mga pagkakasunud-sunod ay nagsisilbing mga signal na kinikilala ng RNA polymerases. Ang panimulang punto ay karaniwang kinakatawan ng purine. Kaagad sa kaliwa nito ay 6-9 bp, na kilala bilang Pribnov sequence (o kahon): TATAAT. Ito ay maaaring medyo mag-iba, ngunit ang unang dalawang base ay nangyayari sa karamihan ng mga tagapagtaguyod. Ipinapalagay na dahil ito ay nabuo ng isang site na mayaman sa mga pares ng AT, na naka-link sa pamamagitan ng dalawang hydrogen bond, ang DNA sa lugar na ito ay mas madaling ihiwalay sa magkahiwalay na mga hibla. Lumilikha ito ng mga kondisyon para sa paggana ng RNA polymerase. Kasama nito, ang Pribnov box ay kinakailangan para sa oryentasyon sa paraang ang mRNA synthesis ay mula kaliwa pakanan, ibig sabihin, mula 5`-3`. Ang sentro ng Pribnow box ay nasa nucleotide -10. Ang isang sequence ng katulad na komposisyon ay matatagpuan sa ibang rehiyon na nakasentro sa posisyon 35. Ang 9 bp na rehiyon na ito ay tinutukoy bilang sequence 35 o ang recognition region. Ito ang site kung saan nakakabit ang kadahilanan, sa gayon ay tinutukoy ang kahusayan kung saan ang RNA polymerase ay hindi maaaring magsimula ng transkripsyon nang walang mga espesyal na protina. Isa na rito ang CAP o CRP factor.
Sa mga eukaryotes, ang mga promotor na nakikipag-ugnayan sa RNA polymerase II ay pinag-aralan nang mas detalyado. Naglalaman ang mga ito ng tatlong homologous na rehiyon sa mga rehiyon na may mga coordinate sa mga puntong -25, -27 at gayundin sa panimulang punto. Ang mga panimulang base ay mga adenine na nasa magkabilang panig ng mga pyrimidine. Sa layo na 19-25 b.p. sa kaliwa ng site ay 7 b.p. Ang TATAA, na kilala bilang TATA sequence, o Hogness box, ay kadalasang napapalibutan ng mga lugar na mayaman sa mga pares ng GC. Higit pa sa kaliwa, sa posisyon -70 hanggang -80, ay ang sequence ng GTZ o CAATCT, na tinatawag na CAAT box. Ipinapalagay na kinokontrol ng sequence ng TATA ang pagpili ng panimulang nucleotide, habang kinokontrol ng CAAT ang pangunahing pagbubuklod ng RNA polymerase sa template ng DNA.
Pagpahaba. Ang hakbang sa pagpapahaba ng mRNA ay katulad ng pagpapahaba ng DNA. Nangangailangan ito ng ribonucleotide triphosphate bilang mga precursor. Ang yugto ng pagpapahaba ng transkripsyon, iyon ay, ang paglago ng chain ng mRNA, ay nangyayari sa pamamagitan ng paglakip ng ribonucleotide monophosphates sa 3'-end ng chain na may paglabas ng pyrophosphate. Ang pagkopya sa mga eukaryote ay karaniwang nangyayari sa isang limitadong rehiyon ng DNA (gene), bagaman sa mga prokaryote, sa ilang mga kaso, ang transkripsyon ay maaaring magpatuloy nang sunud-sunod sa pamamagitan ng ilang naka-link na mga gene na bumubuo ng isang operon at isang karaniwang tagataguyod. Sa kasong ito, nabuo ang polycistronic mRNA.
Regulasyon ng aktibidad ng gene sa halimbawa ng lactose operon.
Ang lactose operon ay isang bacterial polycistronic operon na naka-encode ng mga gene para sa lactose metabolism.
Ang regulasyon ng lactose metabolism gene expression sa Escherichia coli ay unang inilarawan noong 1961 ng mga siyentipiko na sina F. Jacob at J. Monod. Ang bacterial cell ay synthesize ang mga enzyme na kasangkot sa metabolismo ng lactose lamang kapag ang lactose ay naroroon sa kapaligiran at ang cell ay kulang sa glucose.
Ang lactose operon ay binubuo ng tatlong structural genes, isang promoter, isang operator, at isang terminator. Ipinapalagay na kasama rin sa operon ang regulator gene na nag-encode ng repressor protein.
Mga istrukturang gene ng lactose operon - lacZ, lacY at lacA:
Ang lacZ ay nag-encode ng enzyme β-galactosidase, na naghahati sa disaccharide lactose sa glucose at galactose,
lacY code para sa β-galactoside permease, isang membrane transport protein na nagdadala ng lactose sa cell.
lacA code para sa β-galactoside transacetylase, isang enzyme na naglilipat ng isang acetyl group mula sa acetyl-CoA patungo sa beta-galactosides.
Sa simula ng bawat operon ay isang espesyal na gene - ang operator gene. Sa mga istrukturang gene ng isang operon, karaniwang nabuo ang isang mRNA, at ang mga gene na ito ay aktibo o hindi aktibo sa parehong oras. Bilang isang patakaran, ang mga istrukturang gene sa operon ay nasa isang estado ng panunupil.
Ang promoter ay isang rehiyon ng DNA na kinikilala ng RNA polymerase enzyme, na nagsisiguro sa synthesis ng mRNA sa operon; ito ay pinangungunahan ng isang rehiyon ng DNA kung saan ang Sar protein, isang activator protein, ay nakakabit. Ang dalawang seksyong ito ng DNA ay 85 base pairs ang haba. Pagkatapos ng promoter, ang operon ay nagho-host ng operator gene, na binubuo ng 21 na mga pares ng nucleotide. Karaniwan itong nauugnay sa repressor protein na ginawa ng regulator gene. Sa likod ng operator gene ay isang spacer (space-gap). Ang mga spacer ay mga hindi nagbibigay-kaalaman na mga seksyon ng molekula ng DNA na may iba't ibang haba (kung minsan hanggang 20,000 pares ng base), na, tila, ay kasangkot sa regulasyon ng proseso ng transkripsyon ng kalapit na gene.
Nagtatapos ang operon sa isang terminator - isang maliit na seksyon ng DNA na nagsisilbing stop signal para sa synthesis ng mRNA sa operon na ito.
Ang mga gene ng acceptor ay nagsisilbing mga site para sa attachment ng iba't ibang mga protina na kumokontrol sa paggana ng mga istrukturang gene. Kung ang lactose, na tumagos sa cell (sa kasong ito, ito ay tinatawag na isang inducer), hinaharangan ang mga protina na naka-encode ng regulator gene, pagkatapos ay mawawala ang kanilang kakayahang mag-attach sa operator gene. Ang operator ng gene ay napupunta sa isang aktibong estado at i-on ang mga istrukturang gene.
Ang RNA polymerase, gamit ang Cap protein (activator protein), ay nakakabit sa promoter at, gumagalaw kasama ang operon, nag-synthesize ng pro-mRNA. Sa panahon ng transkripsyon, binabasa ng mRNA ang genetic na impormasyon mula sa lahat ng structural genes sa isang operon. Sa panahon ng pagsasalin, maraming iba't ibang mga polypeptide chain ang na-synthesize sa ribosome, alinsunod sa mga codon na nakapaloob sa mRNA - nucleotide sequence na nagsisiguro sa pagsisimula at pagwawakas ng pagsasalin ng bawat chain. Ang uri ng regulasyon ng gawain ng mga gene, na isinasaalang-alang sa halimbawa ng lactose operon, ay tinatawag na negatibong induction ng synthesis ng protina.
Regulasyon ng aktibidad ng gene sa halimbawa ng tryptophan operon.
Ang isa pang uri ng regulasyon ng gene ay negatibong panunupil, na pinag-aralan sa E.coU gamit ang halimbawa ng operon na kumokontrol sa synthesis ng tryptophone amino acid. Ang operon na ito ay binubuo ng 6700 base pairs at naglalaman ng 5 structural genes, isang operator gene at dalawang promoter. Tinitiyak ng regulator gene ang patuloy na synthesis ng regulatory protein, na hindi nakakaapekto sa paggana ng trp operon. Sa labis na tryptophan sa cell, ang huli ay pinagsama sa regulatory protein at binabago ito sa paraang ito ay nagbubuklod sa operon at pinipigilan ang synthesis ng kaukulang mRNA.
Negatibo at positibong kontrol sa aktibidad ng genetic.
Ang tinatawag na positibong induction ay kilala rin, kapag ang produkto ng protina ng regulator gene ay nagpapagana sa gawain ng operon, i.e. ay hindi isang repressor, ngunit isang activator. Ang dibisyon na ito ay may kondisyon, at ang istraktura ng acceptor na bahagi ng operon, ang pagkilos ng regulator gene sa prokaryotes ay napaka-magkakaibang.
Ang bilang ng mga istrukturang gene sa operon sa mga prokaryote ay mula isa hanggang labindalawa; Ang isang operon ay maaaring magkaroon ng alinman sa isa o dalawang promoter at isang terminator. Ang lahat ng mga istrukturang gene na naisalokal sa isang operon, bilang panuntunan, ay kinokontrol ang isang sistema ng mga enzyme na nagbibigay ng isang chain ng biochemical reactions. Walang alinlangan, may mga sistema sa cell na nag-uugnay sa regulasyon ng gawain ng ilang mga operon.
Ang mga protina na nagpapagana ng mRNA synthesis ay nakakabit sa unang bahagi ng gene acceptor - operator, at ang mga protina - mga repressor na pumipigil sa mRNA synthesis ay nakakabit sa dulo nito. Ang isang gene ay kinokontrol ng isa sa ilang mga protina, na ang bawat isa ay nakakabit sa isang kaukulang lugar ng pagtanggap. Ang iba't ibang mga gene ay maaaring magkaroon ng mga karaniwang regulator at magkaparehong mga rehiyon ng operator. Ang mga regulatory genes ay hindi kumikilos nang sabay-sabay. Una, ang isa ay agad na nagsasama ng isang grupo ng mga gene, pagkatapos ng ilang sandali ang isa pa - isa pang grupo, i.e. ang regulasyon ng aktibidad ng gene ay nangyayari sa "cascades", at ang protina na synthesize sa isang yugto ay maaaring maging isang regulator ng synthesis ng protina sa susunod na yugto.
Ang istraktura ng mga chromosome. Karyotype. Idiogram. Mga modelo ng istraktura ng mga chromosome.
Ang mga eukaryotic chromosome ay kumplikado. Ang batayan ng chromosome ay isang linear (hindi sarado sa isang singsing) macromolecule ng deoxyribonucleic acid (DNA) na may malaking haba (halimbawa, sa mga molekula ng DNA ng mga chromosome ng tao, mayroong mula 50 hanggang 245 milyong pares ng nitrogenous base). Sa isang stretched form, ang haba ng chromosome ng tao ay maaaring umabot ng 5 cm. Bilang karagdagan, ang chromosome ay may kasamang limang espesyal na protina - H1, H2A, H2B, H3 at H4 (ang tinatawag na mga histone) at isang bilang ng mga hindi- mga protina ng histone. Ang pagkakasunud-sunod ng amino acid ng mga histone ay lubos na natipid at halos hindi naiiba sa iba't ibang grupo ng mga organismo. Sa interphase, ang chromatin ay hindi condensed, ngunit kahit na sa oras na ito ang mga thread nito ay isang complex ng DNA at mga protina. Ang Chromatin ay isang deoxyribonucleoprotein na makikita sa ilalim ng isang light microscope sa anyo ng mga manipis na filament at butil. Ang isang DNA macromolecule ay bumabalot sa paligid ng mga octomer (mga istrukturang binubuo ng walong protina globules) ng mga histone na protina na H2A, H2B, H3 at H4, na bumubuo ng mga istrukturang tinatawag na nucleosome.
Sa pangkalahatan, ang buong disenyo ay medyo nakapagpapaalaala sa mga kuwintas. Ang pagkakasunod-sunod ng naturang mga nucleosome na konektado ng isang H1 na protina ay tinatawag na nucleofilament, o nucleosomal filament, na may diameter na humigit-kumulang 10 nm.
Ang condensed chromosome ay mukhang isang X (madalas na may hindi pantay na mga braso) dahil ang dalawang chromatids na nagreresulta mula sa pagtitiklop ay konektado pa rin sa isa't isa sa centromere. Ang bawat cell ng katawan ng tao ay naglalaman ng eksaktong 46 chromosome. Palaging magkapares ang mga kromosom. Ang isang cell ay palaging may 2 chromosome ng bawat species, ang mga pares ay naiiba sa bawat isa sa haba, hugis at pagkakaroon ng mga pampalapot o paghihigpit.
Centromere - isang espesyal na organisadong seksyon ng chromosome, karaniwan sa parehong mga kapatid na chromatids. Hinahati ng centromere ang katawan ng chromosome sa dalawang braso. Depende sa lokasyon ng pangunahing constriction, ang mga sumusunod na uri ng chromosome ay nakikilala: equal-arm (metacentric), kapag ang centromere ay matatagpuan sa gitna, at ang mga braso ay humigit-kumulang pantay sa haba; hindi pantay na mga braso (submetacentric), kapag ang centromere ay inilipat mula sa gitna ng chromosome, at ang mga braso ay hindi pantay na haba; hugis baras (acrocentric), kapag ang sentromere ay inilipat sa isang dulo ng chromosome at ang isang braso ay napakaikli. Sa ilang chromosome, maaaring may mga pangalawang constriction na naghihiwalay sa isang rehiyon na tinatawag na satellite mula sa katawan ng chromosome.
Ang pag-aaral ng kemikal na organisasyon ng mga chromosome ng eukaryotic cells ay nagpakita na sila ay pangunahing binubuo ng DNA at mga protina. Tulad ng napatunayan ng maraming pag-aaral, ang DNA ay isang materyal na carrier ng mga katangian ng pagmamana at pagkakaiba-iba at naglalaman ng biological na impormasyon - isang programa para sa pagbuo ng isang cell, isang organismo, na isinulat gamit ang isang espesyal na code. Ang mga protina ay bumubuo ng isang makabuluhang bahagi ng sangkap ng mga chromosome (mga 65% ng masa ng mga istrukturang ito). Ang chromosome, bilang isang complex ng mga gene, ay isang evolutionary na itinatag na istraktura na katangian ng lahat ng mga indibidwal ng isang partikular na species. Ang magkaparehong pag-aayos ng mga gene sa chromosome ay may mahalagang papel sa likas na katangian ng kanilang paggana.
Ang isang graphic na representasyon ng isang karyotype na nagpapakita ng mga tampok na istruktura nito ay tinatawag na isang idiogram.
Ang isang set ng mga chromosome na tiyak sa isang partikular na species sa bilang at istraktura ay tinatawag na karyotype.
Mga histone. Istraktura ng mga nucleosome.
Ang mga histone ay ang pangunahing klase ng mga nucleoprotein, ang mga nukleyar na protina na kinakailangan para sa pagpupulong at pag-iimpake ng mga hibla ng DNA sa mga chromosome. Mayroong limang iba't ibang uri ng mga histone, pinangalanang H1/H5, H2A, H2B, H3, H4. Ang pagkakasunud-sunod ng mga amino acid sa mga protina na ito ay halos hindi naiiba sa mga organismo ng iba't ibang antas ng organisasyon. Ang mga histone ay maliit, malakas na pangunahing mga protina na direktang nagbubuklod sa DNA. Ang mga histone ay nakikibahagi sa istrukturang organisasyon ng chromatin, na nagne-neutralize sa mga negatibong sisingilin na phosphate group ng DNA dahil sa mga positibong singil ng mga residue ng amino acid, na ginagawang posible ang siksik na pag-iimpake ng DNA sa nucleus.
Dalawang molekula ng bawat isa sa mga histone na H2A, H2B, H3, at H4 ang bumubuo sa isang octamer na pinagsama sa isang 146 bp na segment ng DNA, na bumubuo ng 1.8 na pagliko ng helix sa ibabaw ng istruktura ng protina. Ang particle na ito na may diameter na 7 nm ay tinatawag na nucleosome. Ang isang seksyon ng DNA (linker DNA) na hindi direktang nakikipag-ugnayan sa histone octamer ay nakikipag-ugnayan sa histone H1.
Ang pangkat ng mga non-histone na protina ay lubos na magkakaiba at kinabibilangan ng mga istrukturang nuklear na protina, maraming enzyme at transcription factor na nauugnay sa ilang partikular na rehiyon ng DNA at kinokontrol ang pagpapahayag ng gene at iba pang mga proseso.
Ang mga histone sa octamer ay may mobile N-terminal fragment ("buntot") ng 20 amino acid, na nakausli mula sa mga nucleosome at mahalaga para sa pagpapanatili ng chromatin structure at pagkontrol sa expression ng gene. Kaya, halimbawa, ang pagbuo (condensation) ng mga chromosome ay nauugnay sa phosphorylation ng mga histones, at ang pagpapahusay ng transkripsyon ay nauugnay sa acetylation ng lysine residues sa kanila. Ang mga detalye ng mekanismo ng regulasyon ay hindi pa ganap na naipaliwanag.
Ang Nucleosome ay isang chromatin subunit na binubuo ng DNA at isang set ng apat na pares ng histone protein H2A, H2B, H3 at H4 ng isang H1 histone molecule. Ang histone H1 ay nagbubuklod sa linker DNA sa pagitan ng dalawang nucleosome.
Ang nucleosome ay ang pangunahing yunit ng chromatin packaging. Binubuo ito ng DNA double helix na nakabalot sa isang partikular na complex ng walong nucleosome histones (ang histone octamer). Ang nucleosome ay isang particle na hugis disc na may diameter na humigit-kumulang 11 nm, na naglalaman ng dalawang kopya ng bawat isa sa mga nucleosomal histones (H2A, H2B, H3, H4). Ang histone octamer ay bumubuo ng isang protina core sa paligid kung saan ay double-stranded DNA (146 nucleotide pares ng DNA bawat histone octamer).
Ang mga nucleosome na bumubuo sa mga fibril ay matatagpuan nang higit pa o hindi gaanong pantay sa kahabaan ng molekula ng DNA sa layong 10–20 nm mula sa isa't isa.
Mga antas ng pag-iimpake ng mga eukaryotic chromosome. chromatin condensation.
Kaya, ang mga antas ng packaging ng DNA ay ang mga sumusunod:
1) Nucleosomal (2.5 na pagliko ng double-stranded DNA sa paligid ng walong molekula ng histone protein).
2) Supernucleosomal - chromatin helix (chromonema).
3) Chromatid - spiralized chromonema.
4) Chromosome - ang ikaapat na antas ng DNA spermalization.
Sa interphase nucleus, ang mga chromosome ay decondensed at kinakatawan ng chromatin. Ang despiralized na rehiyon na naglalaman ng mga gene ay tinatawag na euchromatin (maluwag, fibrous chromatin). Ito ay isang kinakailangang kondisyon para sa transkripsyon. Sa panahon ng pahinga sa pagitan ng mga dibisyon, ang ilang mga seksyon ng chromosome at buong chromosome ay nananatiling compact.
Ang mga spiralized, malakas na batik na mga lugar na ito ay tinatawag na heterochromatin. Hindi sila aktibo para sa transkripsyon. Mayroong facultative at constitutive heterochromatin.
Ang facultative heterochromatin ay nagbibigay-kaalaman, dahil naglalaman ng mga gene at maaaring pumasa sa euchromatin. Sa dalawang homologous chromosome, ang isa ay maaaring heterochromatic. Ang constitutive heterochromatin ay palaging heterochromatic, non-informative (hindi naglalaman ng mga gene), at samakatuwid ay palaging hindi aktibo kaugnay ng transkripsyon.
Ang Chromosomal DNA ay binubuo ng higit sa 108 base pairs, kung saan nabuo ang mga bloke ng impormasyon - ang mga gene ay nakaayos nang linearly. Nag-account sila ng hanggang 25% ng DNA. Ang gene ay isang functional unit ng DNA na naglalaman ng impormasyon para sa synthesis ng polypeptides, o lahat ng RNA. Sa pagitan ng mga gene ay may mga spacer - hindi nagbibigay-kaalaman na mga segment ng DNA na may iba't ibang haba. Ang labis na mga gene ay kinakatawan ng isang malaking bilang - 104 magkaparehong kopya. Ang isang halimbawa ay mga gene para sa t-RNA, r-RNA, histones. Sa DNA, may mga sequence ng parehong nucleotides. Maaari silang maging katamtamang paulit-ulit at lubos na paulit-ulit na mga pagkakasunud-sunod. Ang mga katamtamang paulit-ulit na pagkakasunud-sunod ay umaabot sa 300 base pairs na may mga pag-uulit na 102 - 104 at kadalasang kumakatawan sa mga spacer, mga redundant na gene.
Ang mga paulit-ulit na sequence (105 - 106) ay bumubuo ng constitutive heterochromatin. Humigit-kumulang 75% ng lahat ng chromatin ay hindi kasali sa transkripsyon, nahuhulog ito sa mga paulit-ulit na sequence at hindi na-transcribe na mga spacer.
Paghahanda ng mga paghahanda ng chromosome. Ang paggamit ng colchicine. Hypotonia, pag-aayos at paglamlam.
Depende sa antas ng proliferative na aktibidad ng mga cell ng iba't ibang mga tisyu sa vivo at in vitro, direkta at hindi direktang mga pamamaraan para sa pagkuha ng mga paghahanda ng chromosome ay nakikilala.
1) Ang mga direktang pamamaraan ay ginagamit sa pag-aaral ng mga tisyu na may mataas na aktibidad ng mitotic (bone marrow, chorion at inunan, mga selula ng mga lymph node, mga tisyu ng embryo sa isang maagang yugto ng pag-unlad). Ang mga paghahanda ng chromosome ay direktang inihanda mula sa bagong nakuha na materyal pagkatapos ng espesyal na pagproseso.
2) Kabilang sa mga hindi direktang pamamaraan ang pagkuha ng mga paghahanda ng chromosome mula sa anumang tissue pagkatapos ng paunang paglilinang nito para sa ibang yugto ng panahon.
Mayroong maraming mga pagbabago ng direkta at hindi direktang mga pamamaraan para sa paghahanda ng mga chromosome na paghahanda, gayunpaman, ang mga pangunahing hakbang para sa pagkuha ng mga metaphase plate ay nananatiling hindi nagbabago:
1. Ang paggamit ng colchicine (colcemid) - isang inhibitor ng pagbuo ng mitotic spindle, na humihinto sa paghahati ng cell sa yugto ng metaphase.
2. Hypotonic shock sa paggamit ng mga solusyon ng potassium o sodium salts, na, dahil sa pagkakaiba sa osmotic pressure sa loob at labas ng mga cell, ay nagiging sanhi ng pamamaga at pagkasira ng mga interchromosomal bond. Ang pamamaraang ito ay humahantong sa paghihiwalay ng mga chromosome sa isa't isa, na nag-aambag sa kanilang mas malawak na pagkalat sa mga metaphase plate.
3. Fixation ng mga cell gamit ang glacial acetic acid at ethanol (methanol) sa isang ratio na 3:1 (Carnoy's fixative), na nag-aambag sa pangangalaga ng chromosome structure.
4. Ibinaba ang cell suspension sa mga glass slide.
5. Paglamlam ng mga paghahanda ng chromosome.
Ang isang bilang ng mga pamamaraan ng paglamlam (banding) ay binuo na ginagawang posible upang makilala ang isang kumplikadong mga transverse mark (mga banda, mga banda) sa isang chromosome. Ang bawat chromosome ay nailalarawan sa pamamagitan ng isang tiyak na hanay ng mga banda. Magkaparehong mantsa ang mga homologous chromosome, maliban sa mga polymorphic na rehiyon kung saan naka-localize ang iba't ibang allelic na variant ng mga gene. Ang allelic polymorphism ay katangian ng maraming mga gene at matatagpuan sa karamihan ng mga populasyon. Ang pagtuklas ng mga polymorphism sa antas ng cytogenetic ay walang halaga ng diagnostic.
A. Q-staining. Ang unang paraan ng differential staining ng mga chromosome ay binuo ng Swedish cytologist na si Kaspersson, na ginamit para sa layuning ito ang fluorescent dye acrichin mustard. Sa ilalim ng isang fluorescent microscope sa mga chromosome ay makikita ang mga lugar na may hindi pantay na fluorescence intensity - Q-segment. Ang pamamaraan ay pinakaangkop para sa pag-aaral ng Y chromosome at samakatuwid ay ginagamit upang mabilis na matukoy ang genetic na kasarian, tukuyin ang mga translocation (site exchange) sa pagitan ng X at Y chromosomes o sa pagitan ng Y chromosome at autosome, pati na rin upang tingnan ang isang malaking bilang ng mga cell kapag kinakailangan upang malaman kung ang isang pasyente na may mosaicism sa mga sex chromosome ay may clone ng mga cell na nagdadala ng Y chromosome.
B. G-paglamlam. Pagkatapos ng malawakang pretreatment, kadalasang may trypsin, ang mga chromosome ay nabahiran ng Giemsa stain. Sa ilalim ng isang light microscope, makikita ang liwanag at madilim na mga guhit sa mga chromosome - G-segment. Bagama't ang pag-aayos ng mga segment ng Q ay tumutugma sa mga segment ng G, ang paglamlam ng G ay napatunayang mas sensitibo at kinuha ang lugar ng paglamlam ng Q bilang karaniwang paraan ng pagsusuri ng cytogenetic. Ang G-staining ay nagbibigay ng pinakamahusay na mga resulta sa pag-detect ng maliliit na aberration at marker chromosome (naka-segment na naiiba kaysa sa mga normal na homologous chromosome).
B. Ang R-staining ay nagbibigay ng larawang kabaligtaran ng G-staining. Karaniwang Giemsa stain o acridine orange fluorescent stain ang ginagamit. Ang pamamaraang ito ay nagpapakita ng mga pagkakaiba sa paglamlam ng homologous G- o Q-negative na mga rehiyon ng mga sister chromatids o homologous chromosomes.
Ang D. C-staining ay ginagamit upang suriin ang mga sentromeric na rehiyon ng chromosome (ang mga rehiyong ito ay naglalaman ng constitutive heterochromatin) at ang variable, maliwanag na fluorescent na distal na bahagi ng Y chromosome.
Ginagamit ang E. T-staining upang pag-aralan ang mga telomeric na rehiyon ng mga chromosome. Ang pamamaraan na ito, pati na rin ang paglamlam ng mga rehiyon ng mga nucleolar organizer na may silver nitrate (AgNOR-staining) ay ginagamit upang pinuhin ang mga resulta na nakuha sa pamamagitan ng karaniwang paglamlam ng mga chromosome.
Teksbuk. Sa kabila ng katotohanan na ang tRNA ay mas maliit, ang isang kuwento tungkol sa istraktura, mga tampok, at paggana nito ay nararapat sa isang hiwalay na kabanata.
Kaya, ang tRNA ay isang "adapter", na kinikilala ang tatlong-titik na pagkakasunud-sunod ng genetic code sa isang dulo, na tumutugma dito sa tanging katumbas na amino acid na naayos sa kabilang dulo ng tRNA. Sa dulo ng paglilipat ng RNA na humipo sa messenger RNA, mayroong 3 nucleotide na bumubuo anticodon. Tanging kung ang anticodon ay komplementaryo sa rehiyon ng mRNA ay maaaring sumali ang paglilipat ng RNA dito. Ngunit kahit na sa kasong ito, ang tRNA ay hindi maaaring sumali sa mRNA sa sarili nitong; nangangailangan ito ng tulong ng ribosome, na siyang lugar ng kanilang pakikipag-ugnayan, pati na rin ang aktibong kalahok sa pagsasalin. Halimbawa, ito ay ang ribosome na lumilikha ng mga bono sa pagitan ng mga amino acid na dinala ng tRNA, na bumubuo ng isang chain ng protina.
Ang mga tampok na istruktura ng tRNA ay tinutukoy ng genetic code, iyon ay, ang mga patakaran para sa pagbuo ng isang protina ayon sa isang gene na binabasa ng transfer RNA. Gumagana ang code na ito sa bawat buhay na nilalang sa Earth: ang paglikha ng isang virus ay nakasulat sa parehong tatlong-titik na mga codon na ginagamit upang isulat ang "mga tagubilin sa pagpupulong" ng isang dolphin. Napatunayan sa eksperimento na ang mga gene ng isang buhay na nilalang, na inilagay sa cell ng isa pa, ay perpektong kinopya at isinalin sa mga protina na hindi makikilala mula sa mga gene na nagpaparami sa mga selula ng host. Ang pagkakapareho ng genetic code ay ang batayan para sa paggawa ng binagong E. coli ng mga kolonya ng insulin at maraming iba pang mga enzyme ng tao na ginagamit bilang mga gamot para sa mga tao na ang katawan ay hindi makagawa ng mga ito, o gumawa ng hindi sapat. Sa kabila ng malinaw na pagkakaiba sa pagitan ng mga tao at E. coli, ang mga protina ng tao ay madaling nalikha mula sa mga blueprint ng tao gamit ang isang E. coli copier. Hindi nakakagulat na ang paglipat ng mga RNA ng iba't ibang mga nilalang ay napakaliit na naiiba.

Ang bawat codon mula sa listahang ito, maliban sa tatlo itigil ang mga codon, na nagpapahiwatig ng pagkumpleto ng pagsasalin, ay dapat kilalanin ng paglilipat ng RNA. Isinasagawa ang pagkilala sa pamamagitan ng pag-attach ng isang anticodon sa messenger RNA, na maaari lamang magbigkis sa isang codon mula sa listahan, kaya isang codon lang ang makikilala ng tRNA. Nangangahulugan ito na mayroong hindi bababa sa 61 na uri ng mga molekulang ito sa cell. Sa katunayan, marami pa sa kanila, dahil sa ilang mga sitwasyon para sa pagbabasa ng messenger RNA hindi sapat na magkaroon lamang ng tamang anticodon: kinakailangan ang iba pang mga kondisyon, alinsunod sa kung saan nilikha ang isang espesyal, binagong tRNA.
Sa unang sulyap, ang iba't ibang mga tRNA ay dapat na makabuluhang kumplikado sa proseso ng pagsasalin: pagkatapos ng lahat, ang bawat isa sa mga molekulang ito ay susuriin ang matrix RNA codon na pinalitan para dito ng ribosome para sa pagsunod sa anticodon nito - tila napakaraming walang kabuluhang gawaing mekanikal. , napakaraming nasayang na oras at lakas. Ngunit bilang resulta ng ebolusyon, nabuo din ang mga mekanismo ng cellular na pumipigil sa problemang ito. Halimbawa, ang dami ng tRNA ng bawat species sa isang cell ay tumutugma sa kung gaano kadalas ang amino acid na dala ng species na iyon ay matatagpuan sa mga protina na binuo. May mga amino acid na bihirang ginagamit ng cell, at may mga madalas na ginagamit, at kung ang bilang ng mga tRNA na nagdadala ng mga ito ay pareho, ito ay lubos na magpapalubha sa pagpupulong ng mga protina. Samakatuwid, kakaunti ang mga "bihirang" amino acid at ang kanilang mga kaukulang tRNA sa cell, habang ang mga madalas na nangyayaring amino acid ay ginawa sa malalaking dami.

Sa ganoong iba't ibang mga molekula ng tRNA, lahat sila ay halos magkapareho, samakatuwid, kung isasaalang-alang ang kanilang istraktura at pag-andar, higit na pag-aaralan natin ang mga tampok na karaniwan sa lahat ng mga species. Kapag tiningnan mo ang 3D na layout ng tRNA, mukhang isang siksik na tumpok ng mga atomo. Tila hindi kapani-paniwala na ang masalimuot na nakapulupot na molekula na ito ay resulta ng pagtitiklop ng isang mahabang kadena ng mga nucleotides, ngunit sa ganoong paraan ito nabuo.
Posibleng masubaybayan ang mga yugto ng pagbuo nito, simula sa una: ang pagsasama-sama ng isang nucleotide sequence ng RNA polymerase alinsunod sa gene na naglalaman ng impormasyon tungkol sa paglilipat ng RNA na ito. Ang pagkakasunud-sunod ng mga nucleotide na ito ay sumusunod sa isa't isa at ang kanilang bilang ay tinatawag pangunahing istraktura ng tRNA. Lumalabas na ito ang pangunahing istraktura ng tRNA na naka-encode sa gene na binasa ng RNA polymerase. Sa pangkalahatan, ang pangunahing istraktura ay isang pagkakasunud-sunod ng medyo simpleng mga molekula ng parehong uri, na bumubuo ng isang mas kumplikado, nakatiklop na molekula ng polimer. Halimbawa, ang pangunahing istraktura ng isang molekula ng protina ay ang simpleng pagkakasunud-sunod ng mga bumubuo nitong amino acid.

Ang anumang kadena ng mga nucleotide ay hindi maaaring nasa isang nakabukas na estado sa isang cell, na nakaunat lamang sa isang linya. Napakaraming bahagi ng positibo at negatibong sisingilin sa mga gilid ng nucleotides, na madaling bumubuo ng mga bono ng hydrogen sa isa't isa. Kung paano nabuo ang parehong mga bono sa pagitan ng mga nucleotide ng dalawang molekula ng DNA, na nagkokonekta sa mga ito sa isang double helix, ay inilarawan sa, at maaari kang makakuha ng mga detalye tungkol sa mga bono ng hydrogen. Ang mga hydrogen bond ay hindi gaanong malakas kaysa sa mga bono sa pagitan ng mga atomo sa mga molekula, ngunit sapat na ang mga ito upang maisip na i-twist ang tRNA strand at panatilihin ito sa ganoong posisyon. Sa una, ang mga bono na ito ay nabuo lamang sa pagitan ng ilang mga nucleotide, na natitiklop ang tRNA sa isang hugis na dahon ng klouber. Ang resulta ng paunang pagtitiklop na ito ay tinatawag pangalawang istraktura tRNA. Ang diagram sa kaliwa ay nagpapakita na ang ilang mga nucleotide lamang ang nakaugnay sa pamamagitan ng mga bono ng hydrogen, habang ang iba ay nananatiling hindi magkapares, na bumubuo ng mga singsing at mga loop. Ang mga pagkakaiba sa pagitan ng pangalawang istraktura ng iba't ibang uri ng tRNA ay dahil sa mga pagkakaiba sa kanilang pangunahing istraktura. Ito ay nagpapakita mismo sa iba't ibang haba ng "mga dahon ng klouber" o "stalk" dahil sa iba't ibang haba ng paunang kadena ng mga nucleotides.
Ang isa pang pagkakaiba sa pangunahing istraktura ng iba't ibang mga tRNA ay na sa ilang mga posisyon lamang mayroon silang parehong mga nucleotide (sa diagram sa itaas ay minarkahan sila ng mga unang titik ng kanilang mga pangalan), habang ang karamihan sa mga nucleotide sa iba't ibang mga tRNA ay naiiba sa bawat isa. Ang scheme sa itaas ay karaniwan sa lahat ng tRNA, kaya ang iba't ibang mga nucleotide ay minarkahan ng mga numero.
Ang mga pangunahing functional na bahagi ng tRNA ay:
=) anticodon, iyon ay, ang nucleotide sequence na pantulong sa isang codon ng messenger RNA na matatagpuan sa anticodon hairpin
=) pagtatapos ng acceptor kung saan maaaring ikabit ang isang amino acid. Ito ay matatagpuan sa tapat ng anticodon hairpin.
Sa katotohanan, walang isang tRNA ang kamukha nito sa pangalawang diagram ng istraktura, dahil ang ilang mga nucleotide lamang ang nagsama-sama upang mabuo ito, habang ang iba ay nanatiling hindi ipinares. Dahil sa pagbuo ng mga bono ng hydrogen sa pagitan ng mga nucleotide mula sa iba't ibang bahagi ng dahon ng klouber, natitiklop pa ito sa isang mas kumplikadong tersiyaryong istraktura sa hugis ng isang L. Maaari mong maunawaan nang eksakto kung paano ang iba't ibang bahagi ng pangalawang istraktura ay kurbadong upang mabuo ang tertiary na istraktura sa pamamagitan ng pagtutugma ng mga kulay sa kanilang mga diagram sa ibaba. Ang anticodon hairpin, na minarkahan ng asul at kulay abo, ay nananatili sa ibaba (karapat-dapat na alalahanin na ang "ibaba" na ito ay may kondisyon: ito ay maginhawa upang ilarawan ang tRNA sa spatial na oryentasyong ito sa mga scheme ng pagsasalin ng protina), at ang acceptor end (dilaw) ay nakayuko sa gilid.

Ito ang hitsura ng tRNA kapag handa na itong ilakip ang isang amino acid. Ang tRNA ay hindi kayang pagsamahin sa amino acid sa sarili nitong, ito ay nangangailangan ng pakikilahok ng isang espesyal na enzyme: aminoacyl-tRNA synthetases. Ang bilang ng mga uri ng synthetase sa isang cell ay tumutugma sa bilang ng mga uri ng tRNA.
Ang pagkakapareho ng hugis ng lahat ng uri ng tRNA ay kinakailangan upang ang ribosome ay makilala ang alinman sa mga ito, mapadali ang kanilang docking sa mRNA, at lumipat sa loob mismo mula sa isang site patungo sa isa pa. Kung ang iba't ibang uri ng tRNA ay makabuluhang naiiba sa isa't isa, ito ay magpapahirap sa gawain ng ribosome, na kritikal na binabawasan ang rate ng synthesis ng protina. Ang natural na pagpili ay naglalayong gawin ang mga tRNA na magkatulad sa bawat isa. Ngunit sa parehong oras, mayroong isa pang kadahilanan na nangangailangan ng pagkakaroon ng mga kapansin-pansin na pagkakaiba sa pagitan ng iba't ibang uri ng tRNA: pagkatapos ng lahat, kinakailangang kilalanin ang bawat uri at ilakip dito ang tanging kaukulang amino acid. Malinaw, ang mga pagkakaibang ito ay dapat na kapansin-pansin, ngunit hindi masyadong makabuluhan, upang ang gawain ng pagkilala sa mga species ng tRNA ay nagiging isang proseso ng alahas. At tiyak na ito ang isinasagawa ng aminoacyl-tRNA synthetases: ang bawat isa sa kanila ay maaaring magbigkis sa isa lamang sa 20 amino acid at ilakip ito sa tiyak na mga uri ng tRNA na tumutugma sa amino acid na ito. Mula sa talahanayan na may genetic code, makikita na ang bawat amino acid ay naka-encode ng ilang mga nucleotide sequence, samakatuwid, halimbawa, lahat ng apat na tRNA na may anticodons CGA, CGG, CGU at CGC ay makikilala ng parehong synthetase na nakakabit sa alanine sa kanila. Ang ganitong mga tRNA na naproseso ng isang synthetase ay tinatawag kaugnay.
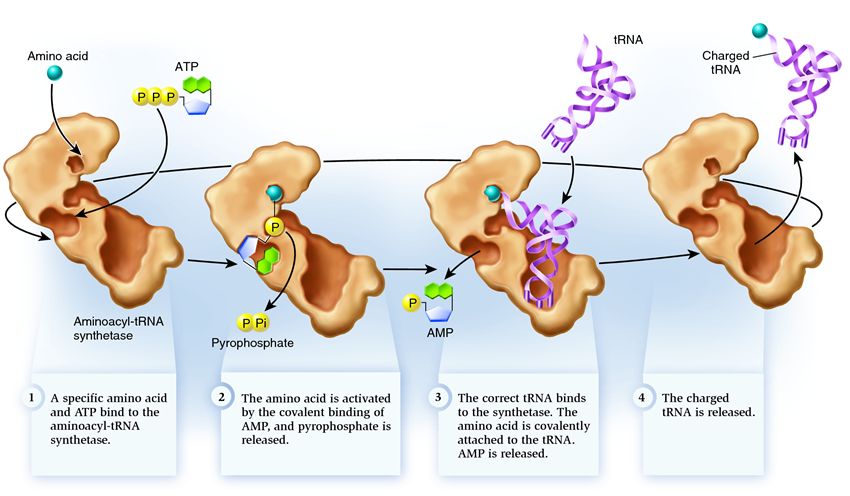
Ang Synthetase ay kabilang sa isang pangkat ng mga enzyme na ang tungkulin ay magbigkis sa magkahiwalay na umiiral na mga molekula at pagsamahin ang mga ito sa isa:
1 . Ang synthetase ay nag-uugnay sa isang amino acid at isang molekula ng ATP. Dalawang grupo ng pospeyt ang humiwalay sa ATP, na naglalabas ng enerhiya na kailangan para sa mga sumusunod na aktibidad. Ang adenosine monophosphate (AMP) na natitira mula sa nawasak na molekula ay nakakabit sa amino acid, inihahanda ito para sa koneksyon sa acceptor hairpin.
2 . Ang synthetase ay nakakabit sa sarili nitong isa sa mga nauugnay na tRNA na naaayon sa amino acid na ito.

Sa yugtong ito, sinusuri ang conformity ng transfer RNA sa synthetase. Mayroong ilang mga paraan ng pagkilala, at ang bawat synthetase ay may natatanging kumbinasyon ng mga ito. Hindi bababa sa isang anticodon nucleotide ang kasangkot sa pakikipag-ugnayan sa pagitan ng synthetase at tRNA. Kailangan ding suriin ang acceptor hairpin: ang pagkakaroon ng mga partikular na nucleotide dito na karaniwan sa mga nauugnay na tRNA na naaayon sa nais na amino acid ay tinutukoy. Ang mga nucleotide mula sa ibang bahagi ng tRNA ay maaari ding lumahok sa pagtutugma sa pamamagitan ng pagbubuklod sa ilang partikular na synthetase site. Ang maling tRNA ay maaaring tumugma sa ninanais sa ilang paraan, ngunit dahil sa hindi kumpletong pagtutugma, ito ay sasali sa synthetase nang dahan-dahan at maluwag, na madaling mahulog. At ang tamang tRNA ay mananatili sa synthetase nang mabilis at matatag, bilang isang resulta kung saan nagbabago ang istraktura ng synthetase, na nagsisimula sa proseso. aminoacylation , iyon ay, ang attachment ng isang amino acid sa tRNA.

3 . Binubuo ang aminoacylation sa pagpapalit ng molekula ng AMP na nakakabit sa amino acid ng isang molekula ng tRNA. Pagkatapos ng pagpapalit na ito, iniiwan ng AMP ang synthetase at pinapanatili ang tRNA para sa isang huling pagsusuri ng amino acid. Kung ang nakakabit na amino acid ay kinikilalang hindi tama, ito ay mahihiwalay sa tRNA, ang lugar ng amino acid sa synthetase ay magiging walang laman, at isa pang molekula ang maaaring sumali doon. Ang bagong amino acid ay dadaan sa mga yugto ng koneksyon sa ATP at tRNA, at susuriin din. Kung walang pagkakamali, ang tRNA na sinisingil ng amino acid ay inilabas: handa itong gampanan ang papel nito sa pagsasalin ng protina. At handa na ang synthetase na mag-attach ng mga bagong amino acid at tRNA, at magsisimula muli ang cycle.
Marami ang nakasalalay sa tamang operasyon ng aminoacyl-tRNA synthetase: kung ang isang pagkabigo ay nangyari sa yugtong ito, kung gayon ang maling amino acid ay ikakabit sa tRNA. At ito ay itatayo sa protina na lumalaki sa ribosome, dahil ang tRNA at ang ribosome ay walang function na suriin ang mga sulat ng codon at amino acid. Ang mga kahihinatnan ng pagkakamali ay maaaring maliit o sakuna, at sa pamamagitan ng natural na pagpili, ang mga nilalang na may mga enzyme na walang function ng naturang mga tseke ay napalitan ng mga mas madaling ibagay na may iba't ibang mga opsyon para sa pagtutugma sa pagitan ng amino acid at tRNA. Samakatuwid, sa mga modernong cell, ang synthetase ay pinagsama sa maling amino acid sa karaniwan sa isang kaso sa 50 libo, at sa maling tRNA isang beses lamang sa 100 libong mga attachment.

Ang ilang mga amino acid ay naiiba sa bawat isa sa pamamagitan lamang ng ilang mga atomo. Kung titingnan mo ang kanilang mga scheme, nagiging halata na ang posibilidad na malito ang arginine sa alanine ay mas mababa kaysa sa nakalilitong isoleucine para sa leucine o valine. Samakatuwid, ang bawat synthetase na nagbubuklod sa isa sa mga amino acid na katulad ng bawat isa ay may mga karagdagang mekanismo ng pag-verify. Narito ang isang halimbawa ng naturang adaptation sa isoleucine-tRNA synthetase:

Ang bawat synthase ay mayroon sintetikong sentro kung saan ang isang amino acid ay nakakabit sa isang tRNA. Ang acceptor hairpin ng tRNA na nakunan ng synthetase ay napupunta doon, gayundin ang amino acid na handang tumugon dito. Ang gawain ng ilang mga synthetases ay nagtatapos kaagad pagkatapos ng koneksyon ng amino acid at tRNA. Ngunit ang Ile-tRNA synthetase ay may mas mataas na pagkakataon na magkamali dahil sa pagkakaroon ng iba pang mga amino acid na tulad ng isoleucine. Samakatuwid, mayroon din siya sentro ng pagwawasto: mula sa pangalan ay malinaw kung ano ang papel na ginagampanan nito sa proseso ng pagkonekta ng tRNA at amino acids. Ang figure sa kanan ay nagpapakita na ang posisyon ng dulo ng tRNA acceptor hairpin sa synthetic center ng Ile-tRNA synthetase ay nagbibigay sa hairpin na ito ng hindi natural na liko. Gayunpaman, ang synthetase ay humahawak sa tRNA sa posisyon na ito hanggang sa ang amino acid ay nakakabit dito. Matapos maganap ang koneksyon na ito, ang pangangailangan upang mahanap ang acceptor hairpin sa sintetikong sentro ay naubos, at ang tRNA ay tumutuwid, na nagtatapos sa amino acid na nakakabit dito sa sentro ng pagwawasto.

Siyempre, ang synthetic center ay gumaganap din ng isang papel sa pag-screen ng mga amino acid na hindi angkop para sa synthetase. Upang makapasok dito, ang molekula ay dapat matugunan ang isang bilang ng mga kundisyon, kabilang ang pagkakaroon ng tamang sukat. Sa kabila ng katotohanan na ang leucine at isoleucine ay naglalaman ng parehong bilang ng mga atomo, dahil sa mga pagkakaiba sa spatial na istraktura, ang leucine ay mas malaki. Samakatuwid, hindi ito maaaring tumagos sa sintetikong sentro, ang laki nito ay tumutugma sa mas siksik na isoleucine, at nagba-bounce lamang sa Ile-tRNA synthetase.
Ngunit ang valine, na siyang pinakamaliit sa tatlong molekulang ito na may katulad na istraktura ng atom, ay madaling pumalit sa isoleucine sa sintetikong sentro, at ikinakabit ito ng synthetase sa tRNA. Ito ay sa kasong ito na ang correctional center ng synthetase ay papasok. Kung ang straightening acceptor hairpin ay wastong na-charge at nagdadala ng isoleucine, kung gayon hindi ito makakapit sa loob ng correction center: ito ay napakaliit lamang para sa molekula na ito. Kaya, ang itinuwid na tRNA ay hindi na hawak ng anumang bagay, at ito ay hiwalay sa synthetase. Ngunit kung ang valine ay nakakabit sa tRNA, dumudulas ito sa sentro ng pagwawasto, sa gayon ay pinapanatili ang tRNA na konektado dito sa synthetase. Ang sobrang mahabang pananatili ng tRNA sa loob ay isang error signal para sa synthetase, na binabago ang spatial configuration nito. Ang resulta:
=) Ang valine ay hiwalay sa tRNA at inalis sa synthetase
=) ang acceptor hairpin ay bumalik sa synthetic site, naghihintay para sa attachment sa amino acid
=) ang synthetase ay nagbubuklod sa isang bagong amino acid, "sinisingil" ang tRNA dito at muling sinusuri kung ang isoleucine ay ginamit para dito.
Ang isang katulad na mekanismo ng dobleng pagkilala ay ginagamit ng iba pang mga synthetases.
Ang synthesis ng rRNA at tRNA precursors ay katulad ng synthesis ng ire-mRNA. Ang pangunahing transcript ng ribosomal RNA ay hindi naglalaman ng mga intron, at sa ilalim ng pagkilos ng mga tiyak na RNases ito ay na-cleaved upang bumuo ng 28S-, 18S-, at 5.8S-pRNA; Ang 5S-pRNA ay na-synthesize sa pakikilahok ng RNA polymerase III.
rRNA at tRNA.
Ang mga pangunahing transcript ng tRNA ay na-convert din sa mga mature na anyo sa pamamagitan ng bahagyang hydrolysis.
Ang lahat ng mga uri ng RNA ay kasangkot sa biosynthesis ng mga protina, ngunit ang kanilang mga pag-andar sa prosesong ito ay naiiba. Ang papel ng matrix na tumutukoy sa pangunahing istruktura ng mga protina ay ginagampanan ng mga messenger RNA (mRNAs). Ang paggamit ng mga cell-free protein biosynthesis system ay napakahalaga para sa pag-aaral ng mga mekanismo ng pagsasalin. Kung ang mga homogenate ng tissue ay natuburan ng pinaghalong mga amino acid, kung saan kahit isa ay may label, kung gayon ang biosynthesis ng protina ay maaaring maitala sa pamamagitan ng pagsasama ng label sa mga protina. Ang pangunahing istraktura ng synthesized na protina ay tinutukoy ng pangunahing istraktura ng mRNA na idinagdag sa system. Kung ang cell-free system ay binubuo ng globin mRNA (maaari itong ihiwalay sa reticulocytes), ang globin ay synthesize (a- at (3-chains ng globin); kung ang albumin ay synthesize mula sa albumin mRNA na nakahiwalay sa hepatocytes, atbp.
14. Halaga ng pagtitiklop:
a) ang proseso ay isang mahalagang mekanismong molekular na pinagbabatayan ng lahat ng uri ng proeukaryotic cell division, b) nagbibigay ng lahat ng uri ng pagpaparami ng parehong unicellular at multicellular na organismo,
c) pinapanatili ang katatagan ng cellular
komposisyon ng mga organo, tisyu at organismo bilang resulta ng physiological regeneration
d) tinitiyak ang pangmatagalang pag-iral ng mga indibidwal na indibidwal;
e) tinitiyak ang pangmatagalang pagkakaroon ng mga species ng mga organismo;
e) ang proseso ay nag-aambag sa eksaktong pagdodoble ng impormasyon;
g) ang mga error (mutations) ay posible sa proseso ng pagtitiklop, na maaaring humantong sa kapansanan sa synthesis ng protina sa pag-unlad ng mga pagbabago sa pathological.
Ang natatanging katangian ng molekula ng DNA na doble bago ang paghahati ng cell ay tinatawag na pagtitiklop.
Mga espesyal na katangian ng katutubong DNA bilang tagapagdala ng namamana na impormasyon:
1) pagtitiklop - ang pagbuo ng mga bagong kadena ay pantulong;
2) self-correction - ang DNA polymerase ay humihiwalay sa mga maling replicated na rehiyon (10-6);
3) reparation - pagpapanumbalik;
Ang pagpapatupad ng mga prosesong ito ay nangyayari sa cell na may pakikilahok ng mga espesyal na enzyme.
Paano gumagana ang sistema ng pag-aayos Ang mga eksperimento na nagsiwalat ng mga mekanismo ng pagkumpuni at ang mismong pagkakaroon ng kakayahang ito ay isinagawa sa tulong ng mga unicellular na organismo. Ngunit ang mga proseso ng pag-aayos ay likas sa mga buhay na selula ng mga hayop at tao. Ang ilang mga tao ay dumaranas ng xeroderma pigmentosum. Ang sakit na ito ay sanhi ng kawalan ng kakayahan ng mga cell na muling i-synthesize ang nasirang DNA. Ang Xeroderma ay namamana. Ano ang sistema ng reparation na ginawa? Ang apat na enzyme na sumusuporta sa proseso ng pag-aayos ay ang DNA helicase, -exonuclease, -polymerase at -ligase. Ang una sa mga compound na ito ay nakikilala ang pinsala sa kadena ng molekula ng deoxyribonucleic acid. Hindi lamang nito kinikilala, ngunit pinuputol din ang kadena sa tamang lugar upang alisin ang nabagong bahagi ng molekula. Ang pag-aalis mismo ay isinasagawa sa tulong ng DNA exonuclease. Susunod, ang isang bagong segment ng molekula ng deoxyribonucleic acid ay na-synthesize mula sa mga amino acid upang ganap na mapalitan ang nasirang segment. Buweno, ang huling chord ng pinaka-komplikadong biological na pamamaraan na ito ay ginaganap gamit ang enzyme DNA ligase. Ito ay responsable para sa paglakip ng synthesized site sa nasirang molekula. Matapos magawa ng lahat ng apat na enzyme ang kanilang trabaho, ang molekula ng DNA ay ganap na na-renew at lahat ng pinsala ay isang bagay ng nakaraan. Ito ay kung paano gumagana ang mga mekanismo sa loob ng isang buhay na cell nang magkakasuwato.
Pag-uuri Sa ngayon, nakikilala ng mga siyentipiko ang mga sumusunod na uri ng sistema ng reparation. Ang mga ito ay isinaaktibo depende sa iba't ibang mga kadahilanan. Kabilang dito ang: Reactivation. pagbawi ng rekombinasyon. Pag-aayos ng heteroduplexes. pag-aayos ng excision. Pagsasama-sama ng mga di-homologous na dulo ng mga molekula ng DNA. Ang lahat ng unicellular na organismo ay may hindi bababa sa tatlong sistema ng enzyme. Ang bawat isa sa kanila ay may kakayahang isagawa ang proseso ng pagbawi. Kabilang sa mga sistemang ito ang: direkta, excisional at postreplicative. Ang mga prokaryote ay nagtataglay ng tatlong uri ng pag-aayos ng DNA. Tulad ng para sa mga eukaryote, mayroon silang mga karagdagang mekanismo sa kanilang pagtatapon, na tinatawag na Miss-mathe at Sos-repair. Detalyadong pinag-aralan ng biology ang lahat ng ganitong uri ng pagpapagaling sa sarili ng genetic material ng mga selula.
15. Ang genetic code ay isang paraan ng pag-encode ng amino acid sequence ng mga protina gamit ang isang sequence ng nucleotides, katangian ng lahat ng buhay na organismo. Ang sequence ng amino acid sa isang molekula ng protina ay naka-encrypt bilang isang sequence ng nucleotide sa isang molekula ng DNA at tinatawag genetic code. Ang rehiyon ng molekula ng DNA na responsable para sa synthesis ng isang solong protina ay tinatawag genome.
Apat na nucleotides ang ginagamit sa DNA - adenine (A), guanine (G), cytosine (C), thymine (T), na sa panitikan sa wikang Ruso ay tinutukoy ng mga titik A, G, C at T. Ang mga titik na ito ay bumubuo ang alpabeto ng genetic code. Sa RNA, ang parehong mga nucleotide ay ginagamit, maliban sa thymine, na pinalitan ng isang katulad na nucleotide - uracil, na tinutukoy ng titik U (U sa panitikan sa wikang Ruso). Sa mga molekula ng DNA at RNA, ang mga nucleotide ay nakahanay sa mga kadena at, sa gayon, ang mga pagkakasunud-sunod ng mga genetic na titik ay nakuha.
Mayroong 20 iba't ibang amino acid na ginagamit sa kalikasan upang bumuo ng mga protina. Ang bawat protina ay isang kadena o ilang mga kadena ng mga amino acid sa isang mahigpit na tinukoy na pagkakasunud-sunod. Tinutukoy ng sequence na ito ang istraktura ng protina, at samakatuwid ang lahat ng mga biological na katangian nito. Ang hanay ng mga amino acid ay pangkalahatan din para sa halos lahat ng nabubuhay na organismo.
Ang pagpapatupad ng genetic na impormasyon sa mga buhay na selula (iyon ay, ang synthesis ng isang protina na naka-encode ng isang gene) ay isinasagawa gamit ang dalawang proseso ng matrix: transkripsyon (iyon ay, mRNA synthesis sa isang DNA matrix) at pagsasalin ng genetic code sa isang pagkakasunud-sunod ng amino acid (synthesis ng isang polypeptide chain sa isang mRNA matrix). Ang tatlong magkakasunod na nucleotides ay sapat na upang mag-encode ng 20 amino acid, pati na rin ang stop signal, na nangangahulugang ang pagtatapos ng pagkakasunud-sunod ng protina. Ang isang set ng tatlong nucleotides ay tinatawag na triplet. Ang mga tinatanggap na pagdadaglat na nauugnay sa mga amino acid at codon ay ipinapakita sa figure.
Mga katangian ng genetic code
Tripletity - isang makabuluhang yunit ng code ay isang kumbinasyon ng tatlong nucleotides (triplet, o codon).
Continuity - walang mga bantas sa pagitan ng triplets, iyon ay, patuloy na binabasa ang impormasyon.
Non-overlapping - ang parehong nucleotide ay hindi maaaring maging bahagi ng dalawa o higit pang triplets sa parehong oras. (Hindi totoo para sa ilang magkakapatong na gene sa mga virus, mitochondria, at bacteria na nag-encode ng maraming frameshift na protina.)
Unambiguity - ang isang tiyak na codon ay tumutugma sa isang amino acid lamang. (Ang property ay hindi pangkalahatan. Ang UGA codon sa Euplotes crassus codes para sa dalawang amino acid, cysteine at selenocysteine)
Pagkabulok (redundancy) - maraming codon ang maaaring tumutugma sa parehong amino acid.
Universality - ang genetic code ay gumagana nang pareho sa mga organismo na may iba't ibang antas ng pagiging kumplikado - mula sa mga virus hanggang sa mga tao (mga pamamaraan ng genetic engineering ay nakabatay dito) (Mayroon ding ilang mga pagbubukod sa property na ito, tingnan ang talahanayan sa "Mga pagkakaiba-iba ng karaniwang genetic code" na seksyon sa artikulong ito).
16.Mga kondisyon para sa biosynthesis
Ang biosynthesis ng protina ay nangangailangan ng genetic na impormasyon ng isang molekula ng DNA; informational RNA - ang carrier ng impormasyong ito mula sa nucleus hanggang sa site ng synthesis; ribosomes - organelles kung saan nangyayari ang aktwal na synthesis ng protina; isang hanay ng mga amino acid sa cytoplasm; transport RNAs encoding amino acids at dinadala ang mga ito sa site ng synthesis sa ribosomes; Ang ATP ay isang sangkap na nagbibigay ng enerhiya para sa proseso ng coding at biosynthesis.
Mga yugto
Transkripsyon- ang proseso ng biosynthesis ng lahat ng uri ng RNA sa DNA matrix, na nagaganap sa nucleus.
Ang isang tiyak na seksyon ng molekula ng DNA ay despiralized, ang mga bono ng hydrogen sa pagitan ng dalawang kadena ay nawasak sa ilalim ng pagkilos ng mga enzyme. Sa isang DNA strand, tulad ng sa isang matrix, ang isang kopya ng RNA ay na-synthesize mula sa mga nucleotides ayon sa komplementaryong prinsipyo. Depende sa rehiyon ng DNA, ang ribosomal, transportasyon, at mga RNA na nagbibigay-kaalaman ay na-synthesize sa ganitong paraan.
Pagkatapos ng synthesis ng mRNA, umalis ito sa nucleus at pumunta sa cytoplasm sa site ng synthesis ng protina sa mga ribosome.
I-broadcast- ang proseso ng synthesis ng polypeptide chain, na isinasagawa sa ribosomes, kung saan ang mRNA ay isang tagapamagitan sa paglilipat ng impormasyon tungkol sa pangunahing istraktura ng protina.
Ang biosynthesis ng protina ay binubuo ng isang serye ng mga reaksyon.
1. Pag-activate at pag-coding ng mga amino acid. Ang tRNA ay may anyo ng isang cloverleaf, sa gitnang loop kung saan mayroong isang triplet anticodon na naaayon sa code ng isang tiyak na amino acid at ang codon sa mRNA. Ang bawat amino acid ay konektado sa kaukulang tRNA gamit ang enerhiya ng ATP. Ang isang tRNA-amino acid complex ay nabuo, na pumapasok sa mga ribosom.
2. Pagbuo ng mRNA-ribosome complex. Ang mRNA sa cytoplasm ay konektado ng mga ribosome sa butil na ER.
3. Pagpupulong ng polypeptide chain. Ang tRNA na may mga amino acid, ayon sa prinsipyo ng complementarity ng anticodon kasama ang codon, ay pinagsama sa mRNA at pumasok sa ribosome. Sa peptide center ng ribosome, isang peptide bond ang nabuo sa pagitan ng dalawang amino acids, at ang pinakawalan na tRNA ay umalis sa ribosome. Kasabay nito, umuusad ang mRNA ng isang triplet sa bawat pagkakataon, na nagpapakilala ng bagong tRNA - isang amino acid at inaalis ang inilabas na tRNA mula sa ribosome. Ang buong proseso ay pinapagana ng ATP. Ang isang mRNA ay maaaring pagsamahin sa ilang mga ribosome, na bumubuo ng isang polysome, kung saan maraming mga molekula ng isang protina ang sabay-sabay na synthesize. Nagtatapos ang synthesis kapag nagsimula ang mga walang kahulugan na codon (stop code) sa mRNA. Ang mga ribosome ay pinaghihiwalay mula sa mRNA, ang mga polypeptide chain ay tinanggal mula sa kanila. Dahil ang buong proseso ng synthesis ay nagaganap sa butil na endoplasmic reticulum, ang mga nagresultang polypeptide chain ay pumapasok sa EPS tubules, kung saan nakuha nila ang pangwakas na istraktura at nagiging mga molekula ng protina.
Ang lahat ng mga reaksyon ng synthesis ay na-catalyzed ng mga espesyal na enzyme gamit ang enerhiya ng ATP. Ang rate ng synthesis ay napakataas at depende sa haba ng polypeptide. Halimbawa, sa ribosome ng Escherichia coli, ang isang protina ng 300 amino acid ay na-synthesize sa humigit-kumulang 15-20 segundo.
Ay ang synthesis ng isang molekula ng protina batay sa messenger RNA (pagsasalin). Gayunpaman, hindi tulad ng transkripsyon, ang isang nucleotide sequence ay hindi maaaring direktang isalin sa isang amino acid, dahil ang mga compound na ito ay may ibang kemikal na kalikasan. Samakatuwid, ang pagsasalin ay nangangailangan ng isang tagapamagitan sa anyo ng transfer RNA (tRNA), na ang tungkulin ay isalin ang genetic code sa "wika" ng mga amino acid.
Pangkalahatang katangian ng paglilipat ng RNA
Ang mga transfer RNA o tRNA ay maliliit na molekula na naghahatid ng mga amino acid sa lugar ng synthesis ng protina (sa mga ribosom). Ang dami ng ganitong uri ng ribonucleic acid sa cell ay humigit-kumulang 10% ng kabuuang RNA pool.
Tulad ng ibang mga uri ng tRNA, ito ay binubuo ng isang kadena ng ribonucleoside triphosphates. Ang haba ng pagkakasunud-sunod ng nucleotide ay 70-90 na mga yunit, at humigit-kumulang 10% ng komposisyon ng molekula ay nahuhulog sa mga menor de edad na bahagi.
Dahil sa ang katunayan na ang bawat amino acid ay may sariling carrier sa anyo ng tRNA, ang cell ay nag-synthesize ng isang malaking bilang ng mga varieties ng molekula na ito. Depende sa uri ng buhay na organismo, ang tagapagpahiwatig na ito ay nag-iiba mula 80 hanggang 100.
mga function ng tRNA
Ang Transfer RNA ay ang tagapagtustos ng substrate para sa synthesis ng protina, na nangyayari sa mga ribosom. Dahil sa natatanging kakayahang magbigkis pareho sa mga amino acid at sa pagkakasunud-sunod ng template, ang tRNA ay gumaganap bilang isang semantic adapter sa paglilipat ng genetic na impormasyon mula sa anyo ng RNA sa anyo ng isang protina. Ang pakikipag-ugnayan ng naturang tagapamagitan na may isang coding matrix, tulad ng sa transkripsyon, ay batay sa prinsipyo ng complementarity ng nitrogenous bases.
Ang pangunahing pag-andar ng tRNA ay upang tanggapin ang mga unit ng amino acid at dalhin ang mga ito sa apparatus ng synthesis ng protina. Sa likod ng teknikal na prosesong ito ay isang malaking biological na kahulugan - ang pagpapatupad ng genetic code. Ang pagpapatupad ng prosesong ito ay batay sa mga sumusunod na tampok:
- lahat ng mga amino acid ay naka-encode ng nucleotide triplets;
- para sa bawat triplet (o codon) mayroong isang anticodon na bahagi ng tRNA;
- ang bawat tRNA ay maaari lamang magbigkis sa isang tiyak na amino acid.

Kaya, ang pagkakasunud-sunod ng amino acid ng isang protina ay tinutukoy kung aling mga tRNA at sa anong pagkakasunud-sunod ang magkakaugnay na magkakaugnay sa messenger RNA sa panahon ng pagsasalin. Posible ito dahil sa pagkakaroon ng mga functional center sa transfer RNA, ang isa ay responsable para sa pumipili na attachment ng isang amino acid, at ang isa pa para sa pagbubuklod sa isang codon. Samakatuwid, ang mga function at ay malapit na nauugnay.
Istraktura ng paglilipat ng RNA
Ang pagiging natatangi ng tRNA ay nakasalalay sa katotohanan na ang istraktura ng molekular nito ay hindi linear. Kabilang dito ang helical double-stranded na mga seksyon, na tinatawag na stems, at 3 single-stranded na mga loop. Sa hugis, ang conformation na ito ay kahawig ng isang dahon ng klouber.
Sa istraktura ng tRNA, ang mga sumusunod na tangkay ay nakikilala:
- acceptor;
- anticodon;
- dihydrouridyl;
- pseudouridyl;
- karagdagang.
Ang double spiral stems ay naglalaman ng 5 hanggang 7 Watson-Crickson pares. Sa dulo ng stem ng acceptor ay isang maliit na kadena ng hindi magkapares na mga nucleotide, ang 3-hydroxyl na kung saan ay ang site ng attachment ng kaukulang molekula ng amino acid.

Ang istrukturang rehiyon para sa koneksyon sa mRNA ay isa sa mga tRNA loop. Naglalaman ito ng isang anticodon na pandagdag sa semantic triplet. Ito ay ang anticodon at ang accepting end na nagbibigay ng adapter function ng tRNA.
Tertiary na istraktura ng isang molekula
Ang "dahon ng klouber" ay isang pangalawang istraktura ng tRNA, gayunpaman, dahil sa pagtitiklop, ang molekula ay nakakakuha ng hugis-L na conformation, na pinagsasama-sama ng karagdagang mga bono ng hydrogen.
Ang L-form ay ang tertiary na istraktura ng tRNA at binubuo ng dalawang halos patayo na A-RNA helice, na may haba na 7 nm at kapal na 2 nm. Ang anyo ng molekula na ito ay may 2 dulo lamang, ang isa ay may anticodon, at ang isa ay may sentro ng pagtanggap.

Mga tampok ng tRNA na nagbubuklod sa amino acid
Ang pag-activate ng mga amino acid (ang kanilang attachment sa transfer RNA) ay isinasagawa ng aminoacyl-tRNA synthetase. Ang enzyme na ito ay sabay na gumaganap ng 2 mahahalagang function:
- catalyzes ang pagbuo ng isang covalent bond sa pagitan ng 3'-hydroxyl group ng acceptor stem at ang amino acid;
- nagbibigay ng prinsipyo ng selective conformity.
Ang bawat isa sa kanila ay may sariling aminoacyl-tRNA synthetase. Maaari lamang itong makipag-ugnayan sa naaangkop na uri ng molekula ng transportasyon. Nangangahulugan ito na ang anticodon ng huli ay dapat na pantulong sa triplet na pag-encode sa partikular na amino acid na ito. Halimbawa, ang leucine synthetase ay magbubuklod lamang sa tRNA na nakalaan para sa leucine.
Mayroong tatlong nucleotide-binding pockets sa aminoacyl-tRNA synthetase molecule, ang conformation at charge nito ay pantulong sa mga nucleotide ng kaukulang anticodon sa tRNA. Kaya, tinutukoy ng enzyme ang nais na molekula ng transportasyon. Mas madalas, ang nucleotide sequence ng acceptor stem ay nagsisilbing fragment ng pagkilala.
Ang mga molekula ng RNA, hindi katulad ng DNA, ay binuo mula sa isang polynucleotide chain. Gayunpaman, sa chain na ito (para sa rRNA at mRNA) may mga rehiyon na komplementaryo sa isa't isa at maaaring makipag-ugnayan upang bumuo ng mga double helix. Sa kasong ito, ang mga pares ng nucleotide A-U at G-C ay konektado sa pamamagitan ng mga bono ng hydrogen. Ang ganitong mga spiralized na rehiyon (tinatawag silang mga hairpins) ay karaniwang naglalaman ng isang maliit na bilang ng mga pares ng nucleotide (hanggang sa 20-30) at kahalili ng mga hindi nakapulupot na rehiyon.
Ang mga tRNA ay may katangiang pangalawang istraktura. Naglalaman ang mga ito ng apat na helical na seksyon at tatlong (apat) na single-stranded na mga loop. Kapag naglalarawan ng gayong istraktura sa isang eroplano, ang isang pigura ay nakuha, na tinatawag na "dahon ng klouber" (Larawan sa kanan).
Fig. Pangalawang (kanan) at tertiary (kaliwa) na istraktura ng tRNA
Ang lahat ng ilang dosenang iba't ibang tRNA cells ay may isang karaniwang plano ng spatial na istraktura, ngunit naiiba sa mga detalye. Ang mga sumusunod na istrukturang rehiyon ay nakikilala sa tRNA.
1. Acceptor end - sa lahat ng uri ng tRNA mayroon itong komposisyon ng CCA. Ang isang amino acid ay nakakabit sa hydroxyl 3 "-OH ng adenosine na may carboxyl group, na inihahatid ng tRNA na ito sa mga ribosome, kung saan nangyayari ang synthesis ng protina.
2. Anticodon loop - naglalaman ng triplet ng mga nucleotides (anticodons) na partikular para sa bawat tRNA. Ang isang anticodon ay pantulong sa isang mRNA codon. Tinutukoy ng interaksyon ng codon-anticodon ang pagkakasunud-sunod ng mga amino acid sa isang molekula ng protina sa panahon ng synthesis nito sa mga ribosom.
3. Pseudouridyl loop (G, C) - ay kasangkot sa pagbubuklod ng tRNA sa ribosome.
4. Ang dihydrouridyl (D) loop ay kinakailangan para sa pagbubuklod sa enzyme aminoacyl-tRNA synthetase, na kasangkot sa amino acid recognition ng tRNA nito.
5. Karagdagang loop - iba para sa iba't ibang tRNA.
Tertiary na istraktura ng RNA at DNA
Ang spatial na pagsasaayos ng isang helical polynucleotide chain (tertiary structure) ay sapat na naipaliwanag para sa mga molekula ng RNA. Napagtibay na ang mga katutubong molekula ng tRNA ay may humigit-kumulang na parehong istrukturang tersiyaryo, na naiiba sa istraktura ng patag na "dahon ng klouber" (pangalawang istraktura) sa higit na pagiging compact dahil sa pagtiklop ng iba't ibang bahagi ng molekula (tingnan ang figure sa itaas).
Para sa rRNA at mRNA, maaaring mayroong tatlong uri ng tertiary structure depende sa konsentrasyon ng asin at temperatura (Fig. sa ibaba). Ang una ay isang maluwag, hindi maayos na bola o isang nakatuwid na kadena (na may pagtaas sa temperatura at kawalan ng mga asing-gamot). Pangalawang opsyon - compact coil na may double helix sections (mataas na ionic strength, room temperature). Ang pangatlong uri ay isang compact rod na may pag-order ng oriented double helical regions (mababang ionic strength, room temperature). Ang lahat ng tatlong uri ng RNA tertiary structure ay konektado sa pamamagitan ng mutual transition.
Ang tertiary structure ng DNA ay depende sa kung gaano karaming mga chain ng polynucleotides (isa o dalawa) ang nasa DNA. Sa isang bilang ng mga virus, natagpuan ang single-stranded na DNA ng linear at circular form. Ang double-stranded helical DNA molecules ay maaari ding umiral sa linear at circular form; ang pagbuo ng huli ay sanhi ng covalent bonding ng kanilang mga bukas na dulo.

kanin. Tertiary structure: A - DNA: 1 - linear single-stranded bacteriophage FX174 (at iba pang mga virus); 2 - circular single-stranded DNA ng mga virus at mitochondria; 3 - singsing na double helix ng DNA; B - RNA: 1 - maluwag na gusot o nakatuwid na kadena; 2 - compact stick; 3 - compact na bola
Bilang karagdagan, pinaniniwalaan na ang dobleng helical na mga molekula ng DNA ay umiiral sa mga kromosom sa anyo ng mga pangalawang helical na fragment na konektado sa isa't isa (supercoil). Samakatuwid, ang molekular na timbang ng katutubong DNA ay umaabot sa ilang daang milyon. Samakatuwid, ang mga molekula na may bigat na molekular na 10,000,000 ay mga subunit ng mas malalaking molecular entity (tertiary structure). Ito ay supercoiling na nagsisiguro sa matipid na packaging ng isang malaking molekula ng DNA sa isang chromosome: sa halip na 8 cm ang haba, na maaaring mayroon ito sa isang pinahabang anyo, sumasakop lamang ito ng 5 nm.



